DISTRIBUCIÓN EXPONENCIAL
A pesar de la sencillez analítica de sus funciones de definición, la distribución exponencial tiene una gran utilidad práctica ya que podemos considerarla como un modelo adecuado para la distribución de probabilidad del tiempo de espera entre dos hechos que sigan un proceso de Poisson. De hecho la distribución exponencial puede derivarse de un proceso experimental de Poisson con las mismas características que las que enunciábamos al estudiar la distribución de Poisson, pero tomando como variable aleatoria , en este caso, el tiempo que tarda en producirse un hecho
Obviamente, entonces , la variable aleatoria será continua. Por otro lado existe una relación entre el parámetro a de la distribución exponencial , que más tarde aparecerá , y el parámetro de intensidad del proceso l , esta relación es a = l
Al ser un modelo adecuado para estas situaciones tiene una gran utilidad en los siguientes casos:
· Distribución del tiempo de espera entre sucesos de un proceso de Poisson
· Distribución del tiempo que transcurre hasta que se produce un fallo, si se cumple la condición que la probabilidad de producirse un fallo en un instante no depende del tiempo transcurrido .Aplicaciones en fiabilidad y teoría de la supervivencia.
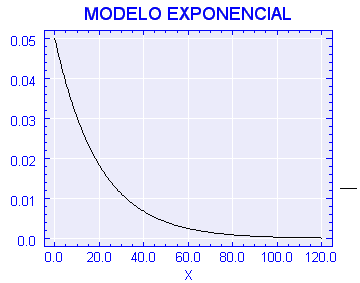 La distribución exponencial
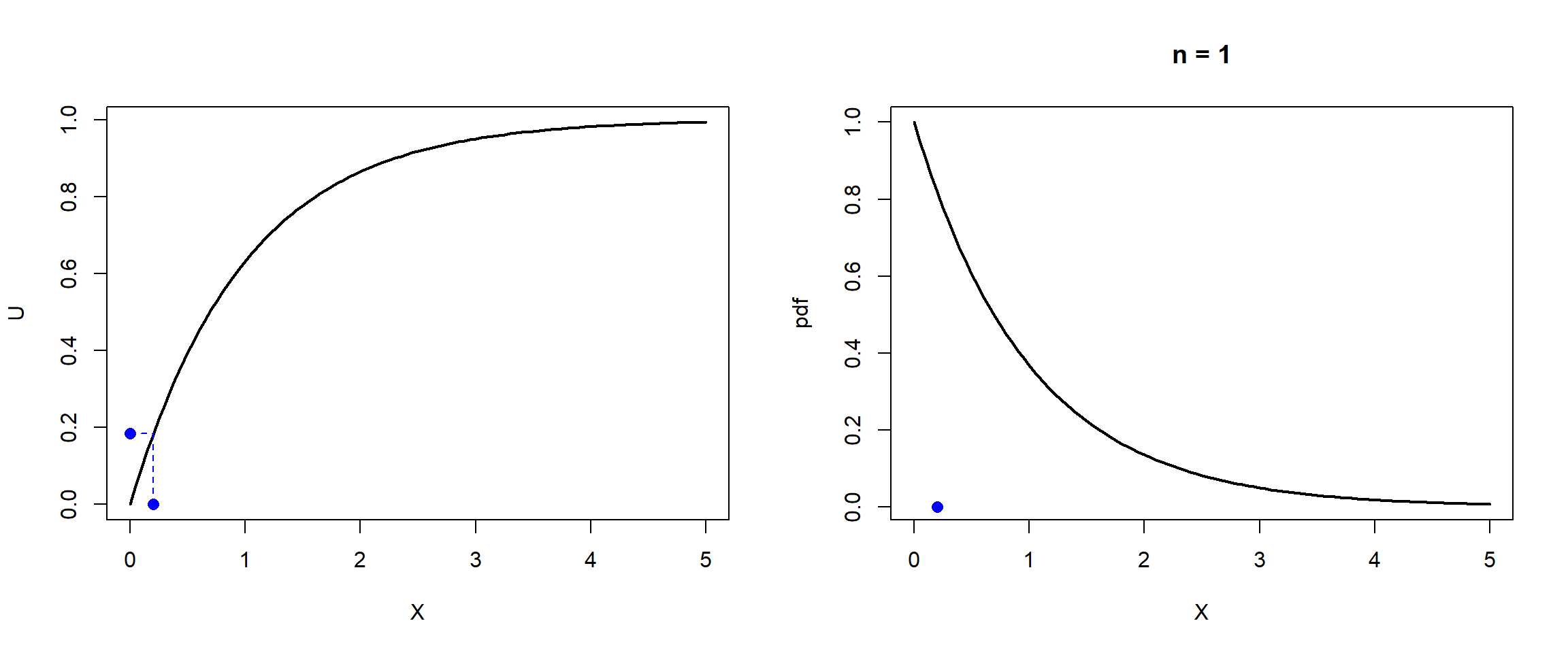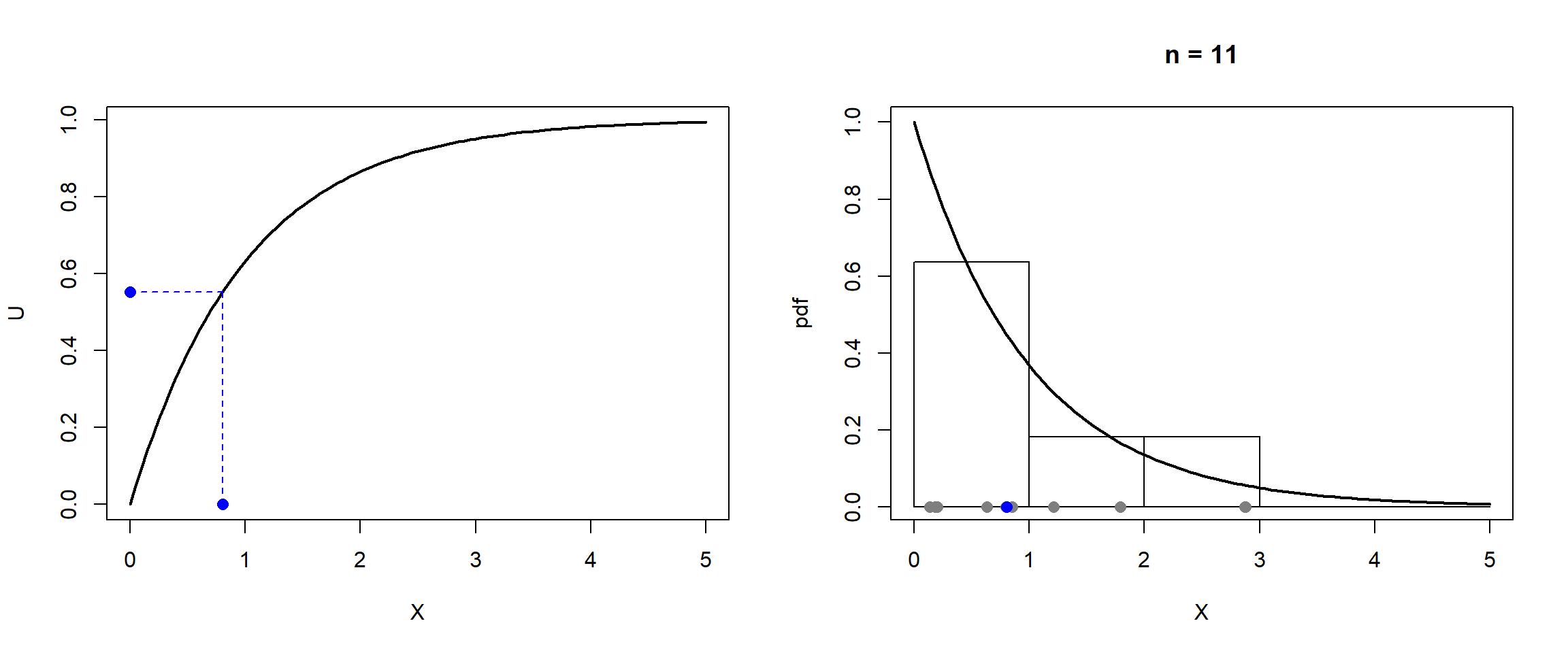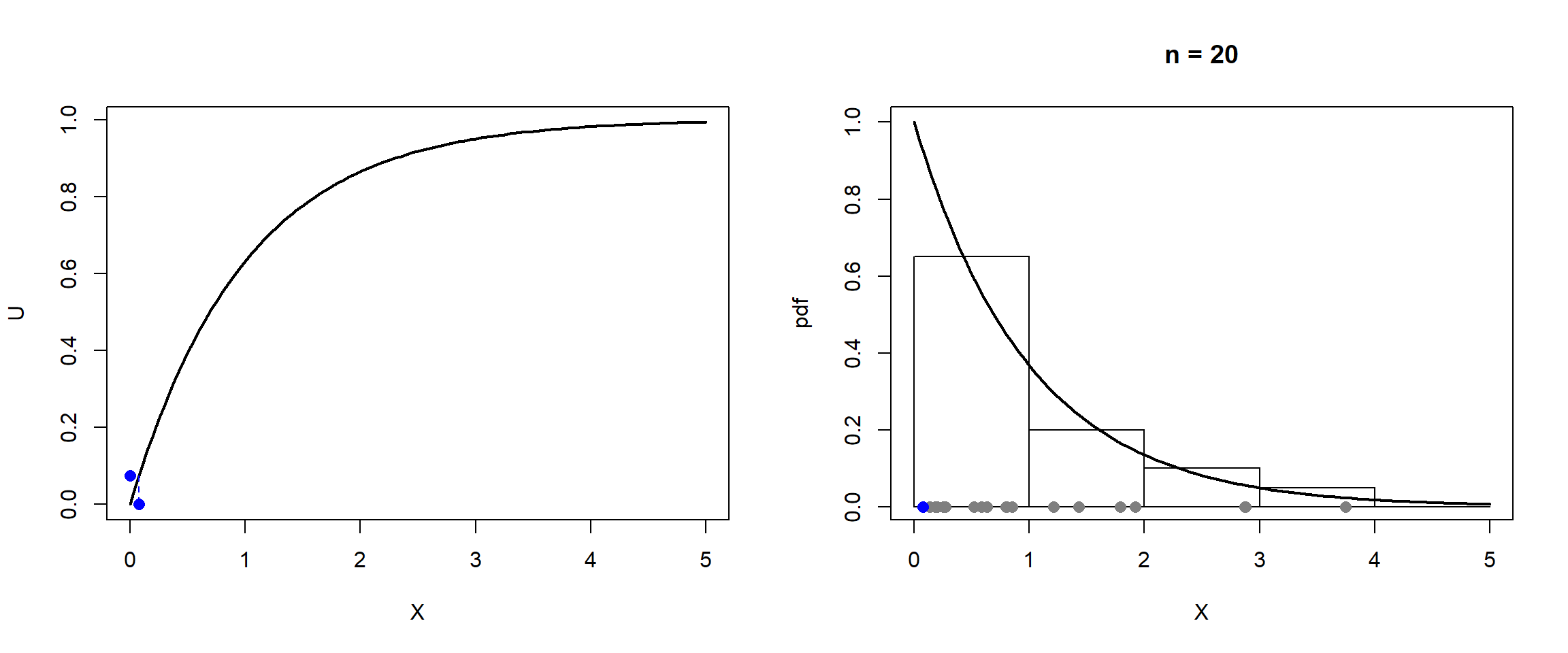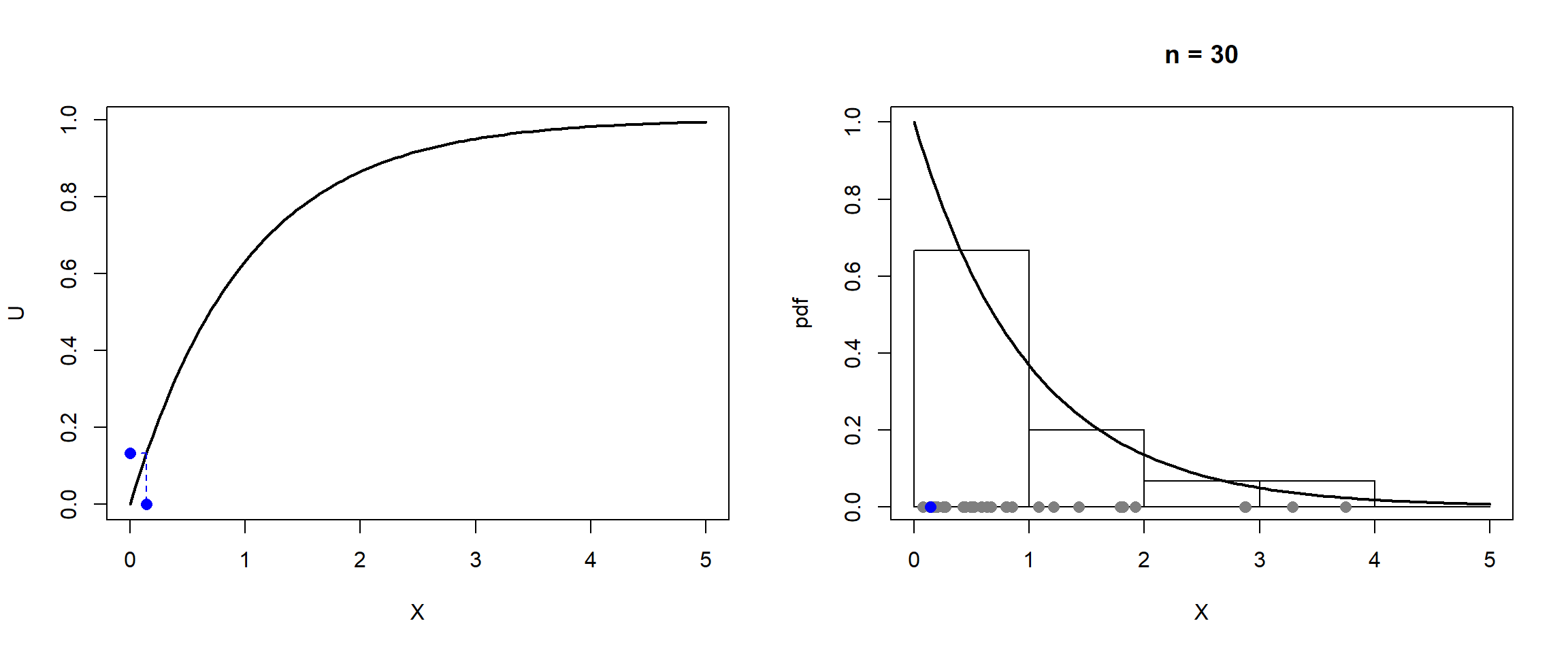
La distribución exponencial de parámetro tiene como función de densidad , si , y como función de distribución:
Teniendo en cuenta que:el algoritmo para simular esta variable mediante el método de inversión es:
Generar .
Devolver .
En el último paso podemos emplear directamente en lugar de , ya que . Esta última expresión para acelerar los cálculos es la que denominaremos forma simplificada.
El código para implementar este algoritmo en R podría ser el siguiente:
tini <- proc.time()
lambda <- 2
nsim <- 10^5
set.seed(1)
U <- runif(nsim)
X <- -log(U)/lambda # -log(1-U)/lambda
tiempo <- proc.time() - tini
tiempo## user system elapsed
## 0.02 0.00 0.01hist(X, breaks = "FD", freq = FALSE,
main = "", xlim = c(0, 5), ylim = c(0, 2.5))
curve(dexp(x, lambda), lwd = 2, add = TRUE)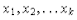



Este comentario ha sido eliminado por el autor.
ResponderBorrarSe entiende muy bien el tema, usa palabras fáciles de comprender y esta bien estructurado, además las imágenes ayudan a tener una imagen más detallada sobre el tema
ResponderBorrarEl tema esta bien hecho 👍🏻
ResponderBorrar